What makes a good dataset sample — and how to create one
In this post, we walk you through how to create a useful dataset sample as a preview of your dataset, and guide you in uploading it to the MDC platform.



Ever downloaded a huge dataset? Watched a Download meter for hours as tens of gigabytes trickle down the internet pipes to your hard drive? Only to then import it into pandas and discover it wasn't quite what you needed?
We share your frustration! That's why providing a high-quality dataset sample is so important, particularly for large datasets. A sample is the "try before you buy" of the data world — a small, representative slice of a larger dataset that lets a potential user assess its suitability before committing to a full download.
In this post, we cover two key pieces: what good sampling practice looks like (and how to do it in code), and how to upload a sample file to accompany your dataset on the Mozilla Data Collective platform.
What makes a good dataset sample?
The case for sampling
Providing a sample alongside a dataset is increasingly considered standard practice in responsible data governance. ISO/IEC 42001:2023, the international standard for AI management systems, emphasises transparency and accessibility in data documentation as a core requirement for trustworthy AI systems. Good sampling practice is part of that picture: it allows downstream users to make informed decisions about whether a dataset meets their needs, before they invest time or compute in a full download.
The FAIR data principles — Findable, Accessible, Interoperable, Reusable — similarly treat dataset transparency as foundational. A sample makes a dataset more assessable, which in turn makes it more reusable. From a practical governance perspective, a sample also gives reviewers, auditors, and ethics boards something concrete to inspect without requiring access to the full dataset.
For large datasets, the download cost alone can be a barrier to evaluation. A well-designed sample removes that barrier and increases the likelihood that your dataset reaches the people who could benefit from it.
Types of sampling and their trade-offs
Not all samples are created equal. The choice of sampling method shapes what a potential user can and cannot infer about the full dataset. The table below summarises the most common approaches.
| Sampling method | What it does | Pros | Cons |
|---|---|---|---|
| Random sampling | Selects rows uniformly at random, without regard for any column values | Simple to implement; no assumptions about dataset structure required | May under-represent rare categories (e.g. minority accents, low-frequency labels); sample composition is non-deterministic |
| Stratified sampling | Samples proportionally from within defined subgroups (strata), such as gender, locale, or age | Preserves the distribution of important categorical variables; more representative of the full dataset | Requires knowing which categories are important before sampling; can be complex if many strata intersect |
| Systematic sampling | Selects every nth row | Simple and deterministic; useful for ordered datasets | Can introduce bias if the data has periodic structure (e.g. repeated patterns every n rows) |
| Purposive / judgement sampling | Manually selects rows to illustrate specific properties | Useful for demonstrating edge cases or data quality characteristics | Not statistically representative; may mislead users about dataset composition |
| Cluster sampling | Randomly selects groups (clusters) and includes all rows from those groups | Efficient for geographically or structurally clustered data | Within-cluster similarity can reduce sample diversity |
For most AI and machine learning dataset use cases, stratified sampling is the recommended approach. It ensures that categorical variables that matter for model training — such as speaker demographics, accent, or label distribution — appear in the sample in proportions that reflect the full dataset, rather than being left to chance.
Creating a representative sample with pandas
The examples below assume you are working with a Common Voice-style dataset in .tsv format, with columns including client_id, sentence_id, sentence, age, gender, accents, and locale. The goal is to produce a sample that is representative across the demographic dimensions that matter most for downstream model training and evaluation.
Step 1: Load the dataset
import pandas as pd
df = pd.read_csv('cv-corpus-en.tsv', sep='\t')
# Preview the shape and column names
print(df.shape)print(df.columns.tolist())Step 2: Inspect the categorical distributions you care about
Before sampling, understand what you have. For a speech dataset, gender and accents are the categories most likely to be unevenly distributed.
print(df['gender'].value_counts(dropna=False))
print(df['accents'].value_counts(dropna=False))You will almost certainly find that some categories are sparse. The accents column in Common Voice datasets, for example, typically has a long tail: a few accent categories contain thousands of clips, while many contain fewer than a hundred. This is not a problem to hide — it is important information for a potential user, and a good sample should reflect it honestly.
Step 3: Stratified sample across gender and accent
# Drop rows where both gender and accents are null,
# since these cannot be assigned to a stratum
df_stratifiable = df.dropna(subset=['gender', 'accents'], how='all')
# Fill remaining nulls with a placeholder so they form their own stratum
df_stratifiable = df_stratifiable.fillna({
'gender': 'not_specified',
'accents': 'not_specified'
})
# Sample proportionally: ~1000 rows, or 1% of the dataset, whichever is smaller
sample_size = min(1000, max(100, int(len(df_stratifiable) * 0.01)))
# groupby + apply with a lambda handles unequal stratum sizes gracefully
sample = (
df_stratifiable
.groupby(['gender', 'accents'], group_keys=False)
.apply(lambda x: x.sample(
n=min(len(x), max(1, int(sample_size * len(x) / len(df_stratifiable)))),
random_state=42
))
.reset_index(drop=True)
)
print(f"Sample size: {len(sample)} rows")
print(sample[['gender', 'accents']].value_counts())
Setting `random_state=42` (or any fixed integer) makes the sample reproducible — the same code will produce the same sample each time. This is important for auditability.
Step 4: Include rows with missing demographic data
A sample that silently drops rows with null `gender` or `accents` values may mislead users about how complete the demographic metadata actually is. Consider explicitly including a small number of such rows:
df_no_demo = df[df['gender'].isna() & df['accents'].isna()]
null_sample = df_no_demo.sample(n=min(20, len(df_no_demo)), random_state=42)
sample = pd.concat([sample, null_sample]).reset_index(drop=True)Step 5: Save the sample
sample.to_csv('cv-corpus-en-sample.tsv', sep='\t', index=False)Sample datasets are a reflection of the integrity of your data
A sample dataset is a claim about the larger dataset it represents.
If your sample over-represents majority categories — because you used random sampling on an imbalanced dataset — users may form incorrect expectations about how useful the dataset is for training models on minority groups. If your sample under-represents them, users may incorrectly conclude the dataset lacks diversity it actually has.
The most honest approach is stratified sampling with clear documentation of what strata were used, including a note on categories with very few examples. If a particular accent or demographic group has fewer than 10 clips in the full dataset, say so in your dataset's Datasheet.
How to upload a sample dataset on the MDC platform
Once you have exported your sample dataset, compress it as a .tar.gz archive. If you're not sure how to do this, our dataset uploading instructions provide more information.
Next, create a new upload submission (you'll need to be approved to upload datasets first). When creating the upload submission, you'll have the opportunity to upload a sample dataset, as shown below.
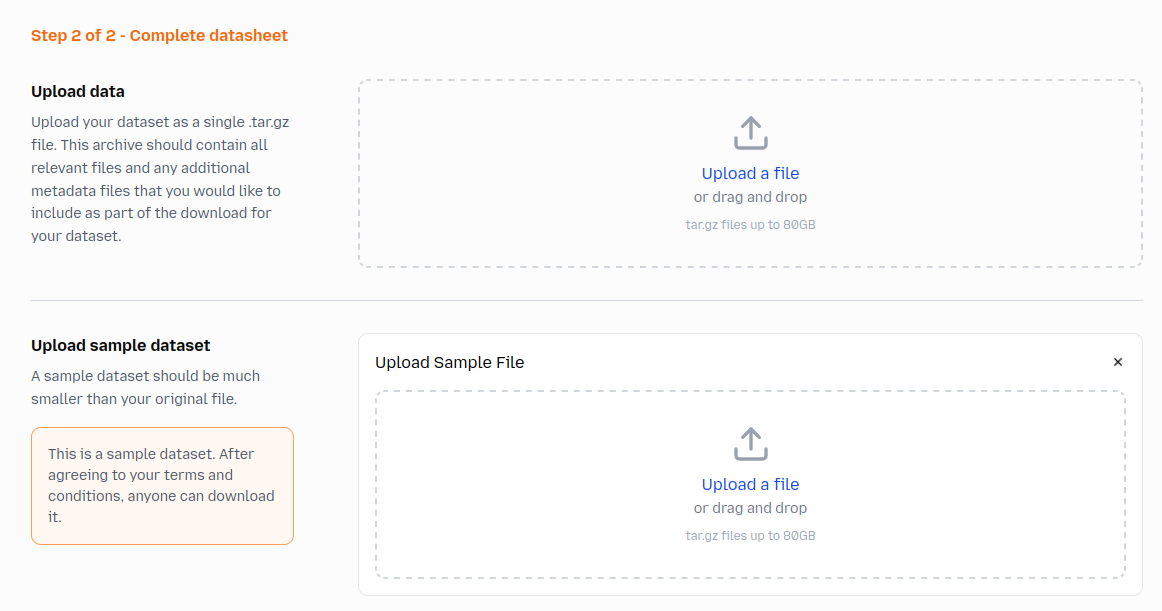
After your dataset submission has been submitted and approved, your sample dataset will be available for download from your dataset's page, as shown below:
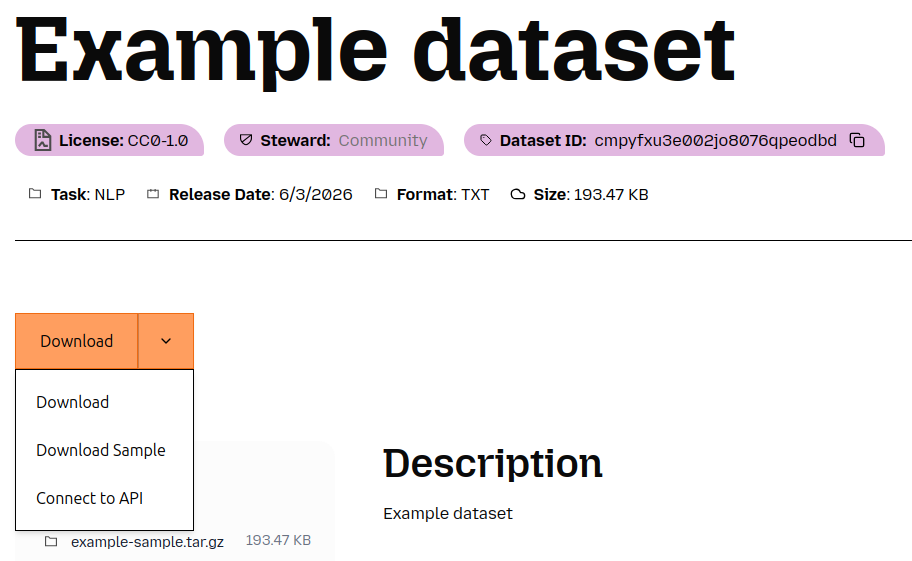
You can also add a dataset sample to existing datasets by viewing your uploads, selecting one, then editing it.
Further reading
- ISO/IEC 42001:2023 — the international standard for AI management systems, which covers data governance and documentation requirements.
- FAIR data principles
- Datasheets for Datasets (Gebru et al., 2021) — the foundational paper on structured dataset documentation.
- pandas documentation on
.sample()


