Pashto becomes third-highest language by volume of data in Common Voice v24
Key highlights from the Common Voice v24 Scripted Speech and v2 Spontaneous Speech release.


We’re delighted to bring you a new dataset release for Common Voice version 24.0 for Scripted Speech, and version 2.0 for Spontaneous Speech. In this blog post, we present key highlights of the release, and show you where you can download the new datasets.
Huge congratulations to the Pashto community for contributing nearly 3000 hours of speech data
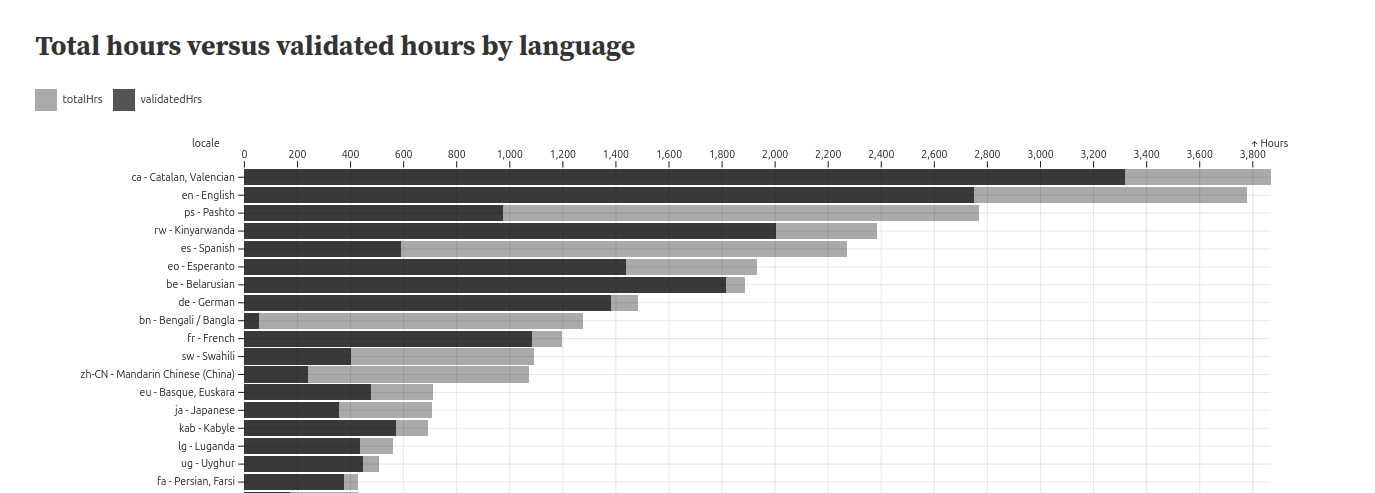
Leading our Common Voice v24 Scripted Speech release are the Pashto language community, who have rocketed to the number three spot by volume of data recorded. In just over three months, the Pashto community have recorded nearly 3,000 hours of audio recordings from nearly 5200 additional speakers, and have validated nearly 1000 hours of recordings.
Pashto is a language spoken in north-western Pakistan and southern and eastern Afghanistan by over 50 million speakers. It is an official language of Afghanistan, alongside Dari. For comparison, the only two languages on Common Voice with more data are Catalan and English. Both these languages have been active on Common Voice for several years.
The Pashto language community overcame several technical barriers to reach this enviable milestone, and we congratulate them for mobilising so effectively to record so much speech data! We’re working to enable Pashto on Spontaneous Speech.
You can join the Pashto language community on Discord here.
You can download the Pashto dataset here.
Special mentions to Alsatian, Irish, Galician, Kabardian, Adyghe, Igbo, and Kurmanji Kurdish!
We would also like to give a special shout out to language communities working on Alsatian, Irish, Galician, Kabardian, Adyghe, French, Igbo, and Kurmanji Kurdish. Targeted campaigns by dedicated volunteers in these communities have achieved laudable outcomes.
Alsatian, new to Common Voice this release, has just started gathering data. Thanks to efforts by Údarás na Gaeltachta, Irish has significantly increased validation efforts in the last three months, with over 80% of all samples now validated thanks. Likewise, Galician, through Project Nós has undertaken significant validation efforts, validating over 50 hours of speech data in the last three months – a commendable achievement!
The Kabardian language community has made spectacular progress, recording over 180 hours of speech, and validating almost all of this data. The closely related Adyghe language has not only recorded another 16 hours of data, they have also validated nearly all of their contributions.
Campaigns in France have added to the already impressive amount of French speech data - now standing at nearly 1200 hours. Igbo, new to Common Voice early this year, have increased their data by over 50% in just three months, with a special shout out to Victoria Ofuasia for all her efforts here. The Kurmanji Kurdish community have also made progress, validating additional data.
Welcome to Common Voice, Lower Sorbian (dsb), Alsatian (gsw) and Laz (lzz)
In this release we welcome to Common Voice three new language communities – Lower Sorbian (dsb), Alsatian (gsw) and Laz (lzz), bringing the total number of languages in Common Voice to 289, from 286 at the last release. A warm welcome to Lower Sorbian, Alsatian and Laz.
- Lower Sorbian (dsb): Lower Sorbian has around 7,000 speakers in Brandenburg, Germany, particularly around the city of Cottbus. It's a West Slavic language that is heavily endangered, with most native speakers belonging to older generations.
Get the Lower Sorbian dataset here. - Alsatian (gsw): Alsatian is spoken in Alsace, a region in north-eastern France, and is an Alemannic German dialect closely related to Swiss German. Alsatian is spoken by around 500,000 speakers.
Get the Alsatian scripted speech dataset here, or the Spontaneous Speech dataset here. - Laz (lzz): Laz has approximately 20,000 native speakers in Turkey and around 1,000 in Georgia. It's spoken along the southeastern shore of the Black Sea, primarily in northeastern Turkey in districts near the Georgian border, and is a Kartvelian language closely related to Mingrelian.
Get the Laz dataset here.
Spontaneous Speech continues to grow
We’ve also increased the number of languages represented in Spontaneous Speech in this release from 58 to 62.
You can see all the Spontaneous Speech datasets at:
https://datacollective.mozillafoundation.org/datasets?q=spontaneous+speech
The English (en) dataset will not be released at this time due to quality issues, however we are planning to include it in the next release.
We are still working on including demographic data such as age, gender and accent of the speaker in the Spontaneous Speech releases, and we expect to include it in the next release. One thing that we do include however are quality tags that are provided for each record in the Spontaneous Speech datasets. You can read more about them here.
Datasets for Dholuo
There will be two datasets for Dholuo luo released. The regular Common Voice dataset for Dholuo is released under the CC-0 public domain license and you can find it here.
The DhoNam: Dholuo Speech dataset is a speech corpus designed to supercharge Automatic Speech Recognition (ASR) and other speech technologies for Dholuo, one of Kenya’s major indigenous languages. This dataset is being released under the Nwulite Obodo Open Data License (NOODL) and has been collected under the supervision of Dr. Lilian Wanzare and with funding provided by GIZ FAIR Forward. This dataset will be released on MDC before the end of the year.
Connect with us
As always, you can connect with us on Discord or Matrix, or contribute speech data at https://commonvoice.mozilla.org, and find all current Common Voice datasets on the Mozilla Data Collective platform.

