Datasheets: The Missing Manual for your Dataset
In this video, produced by the Data Nutrition Project and illustrated by Jessica Yurkofsky, you'll learn more about the role of the datasheet and how you can use it to give clear guidance to potential downloaders about how your data can (and can't!) be used.


When you upload your dataset to Mozilla Data Collective, creating a comprehensive datasheet is a critical part of the process. But what exactly is a datasheet? And how should you think about filling it out?
Creating a comprehensive datasheet adds a lot more value to your dataset. It contextualizes the data that you are sharing, so that downloaders understand how it is intended to be used.
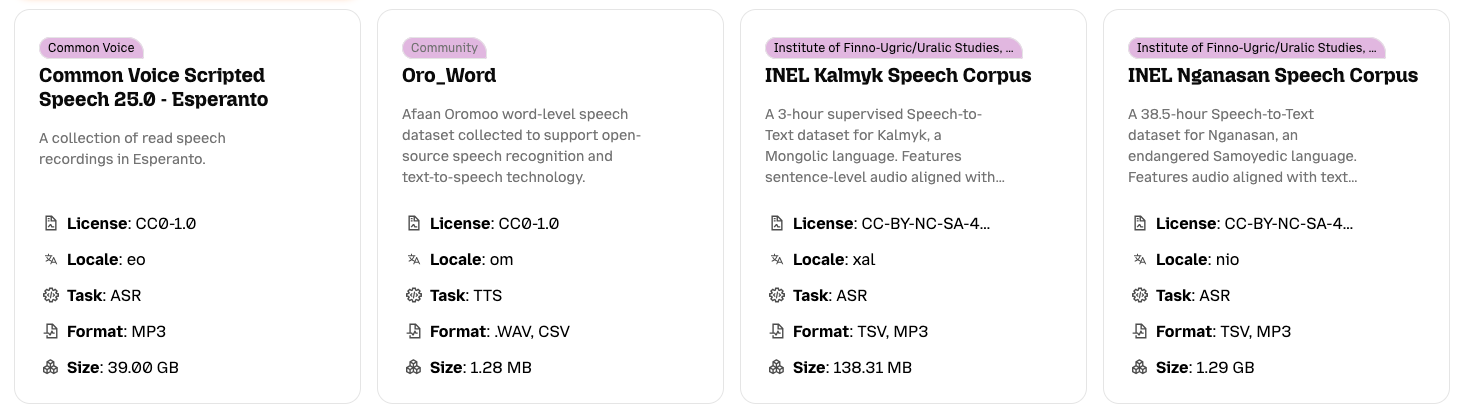
The data card is the first preview that a downloader will have of your dataset. By being specific and clear in these fields, you can help people discover your dataset more easily. Once a potential downloader has found their way to your dataset, your datasheet will help them understand whether it's a good fit for their particular use case.
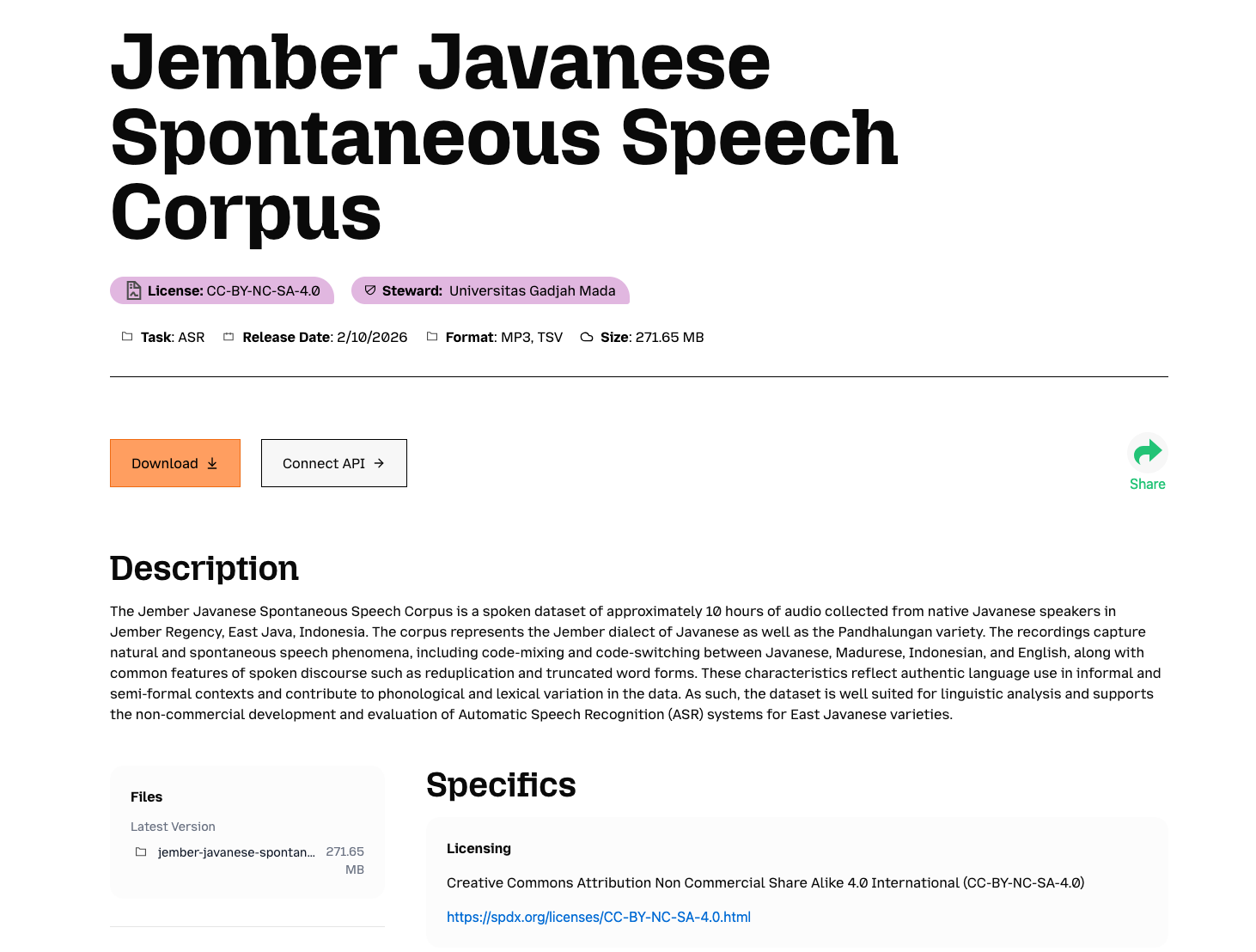
While only some fields in the dataset onboarding form are required, a thorough datasheet is a concrete tool to help individuals and communities share and govern their data.
Additional Resources
Turning Your Data Into a Valuable ML Resource Without Giving Up Control - This guide introduces the principles behind ethical data sharing, ownership, and documentation for community dataset creators
Datasheets for Datasets (Microsoft Research) - Accessible overview of the datasheet concept plus downloadable templates
Data Statements (UW Tech Policy Lab) - Practical framework specifically designed for language and speech datasets, including schema elements covering speaker demographics, annotator demographics, recording quality, and more.
Augmented Datasheets for Speech Datasets (Sony, GitHub Repo) - Sony Research's companion repo to the FAccT 2023 paper, containing the augmented speech datasheet template and completed example datasheets for five datasets including LibriSpeech and Common Voice
Datasheets for Datasets Gebru et al. (2021) - The original paper proposing the datasheet framework, published in Communications of the ACM. Essential reading for understanding the motivation, design decisions, and scope of the datasheet standard
Data Statements for NLP Bender & Friedman (2018) - Proposes a complementary framework specifically for NLP/speech datasets, including speaker demographics, language variety (BCP-47 tags), recording quality, and speech situation; directly applicable to ASR and Common Voice datasets
The Dataset Nutrition Label (2nd gen) Chmielinski et all (2022) - Offers an overview of the 2020 version of the Dataset Nutrition Label
The Data Nutrition Project is empowering data practitioners and policymakers with tools to improve AI outcomes.
Augmented Datasheets for Speech Datasets and Ethical Decision-Making Papakyriakopoulos et al. (2023) - Extends Gebru et al.'s framework with speech-specific questions covering language diversity, accent, dialect, speech impairment, data subject protection, and speaker compensation. Grounded in a large literature review of SLT datasets. Published at ACM FAccT 2023. The most directly relevant paper for documenting ASR datasets such as Common Voice
Data Statements: From Technical Concept to Community Practice McMillan-Major, Bender & Friedman (2024) - Empirical follow-up on how practitioners actually use data statements, with refined schema (v3) and community-developed best practices
Navigating Dataset Cards on Hugging Face (Research Analysis, 2024) - Large-scale empirical analysis of 7,400+ dataset cards on the Hub; reveals what documentation fields are most/least completed and what high-quality cards look like in practice
Animation Credits
Music by: Ricky Valadez
Written by: Sarah Newman & Jessica Yurkofsky
Illustrated by: Jessica Yurkofsky
Read by: Sarah Newman
Sound editing by: Halsey Burgund
Special thanks to Liv Erickson, Katherine Reid, and Francis Tyers
Produced by the Data Nutrition Project in collaboration with Mozilla Data Collective



![On contributing my Thorsten-Voice voice datasets [DE]](/content/images/size/w600/2026/03/pexels-llane-a-3710191.jpg)