
Common Voice
We're Changing Access to Older Versions of Common Voice datasets
We’re tightening the circulation of old datasets to protect contributors, while keeping a clear, documented path for researchers who need them.
Common Voice
We’re tightening the circulation of old datasets to protect contributors, while keeping a clear, documented path for researchers who need them.
FAQ
If you discover a minor issue with the accuracy of a data listing on Mozilla Data Collective (a typo, missing attribute in datasheet, etc.) and want to bring it to the attention of the data provider, reach out to the point of contact as specified in the data listing. If
Join us for the official kick‑off of the Shared Task: Mozilla Common Voice Spontaneous Speech! This live, online gathering will bring together researchers, engineers, and language‑technology enthusiasts from around the world to launch the challenge focused on building robust, multilingual ASR systems for under‑represented languages. In a
FAQ
Mozilla Data Collective wants to provide effective, ethical stewardship support for datasets. This is challenging or impossible when datasets are mirrored or split across a range of forks. Our principles include trying to enable good governance, e.g. the right to be forgotten, as much as possible, which means we
News
Quick links * Registration Form * Link to datasets * Codabench page (to submit results during the testing period) * Contact: sharedtask@mozillafoundation.org Overview Automatic speech recognition (ASR) has come a long way – but most systems are still trained on polished, read-aloud speech. So we set out to build a model that can
Common Voice 23.0 is now live – and available for download via Mozilla Data Collective. Mozilla Data Collective is a sister platform from the team behind Common Voice, designed to let dataset owners and creators offer their data on their own terms. Mozilla Data Collective was built in response to

Mozilla Data Collective is now in live alpha, offering the Common Voice 23.0 datasets.

token
Kathy Reid's presentation to PyConAU in Melbourne, Australia covers tokenomics, harvesting tokens, and how Mozilla Data Collective offers a better way forward.
FAQ
The Mozilla Data Collective REST API provides a way for developers to access datasets from their own applications, using the programming language of their choice. Users must agree to dataset terms through the web interface before downloading. Each download token can only be used for one complete download session, and
FAQ
We have no plans to host Mozilla community datasets through third parties at this time, as it makes governance and stewardship extremely challenging. For example, when someone chooses to revoke their consent to be included in a dataset, we need a way to remove them from the dataset and update
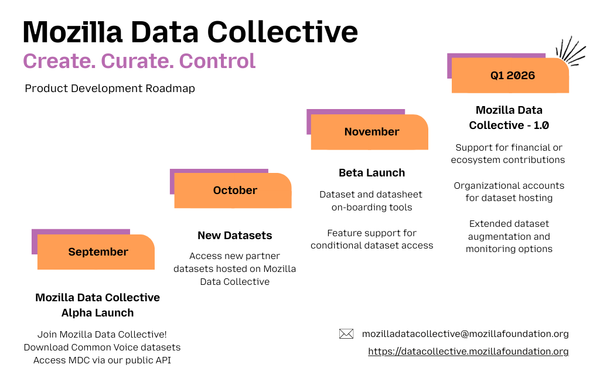
News
We're excited to share a high-level roadmap for the Mozilla Data Collective platform, leading up to our 1.0 launch in early Q1 2026: September: Mozilla Data Collective Alpha Launch October: New Datasets Available November: Mozilla Data Collective Beta Launch * Dataset and datasheet on-boarding and upload flow * Feature
FAQ
We are a mission-driven, community-centred tech organisation being incubated within Mozilla Foundation. Mozilla Data Collective anticipates that we will have both social enterprise and non-profit components eventually, as we think that in today’s volatile, politicised grant funding environment, it’s never been more important to be independent. Our business