MDC Release Notes - 27.02.26
This week: dataset filtering, enhanced uploader request flow, API improvements, and 20 new datasets!


Hello, Mozilla Data Collective! 👋
This week, we've got a lot of new datasets to share with you, as well as a few on-platform updates and improvements that we've made.
New Features and Changes
- There is a new filtering option for dataset searches. Now, you can filter on Task, Language, License, and dataset Format when browsing through the dataset listings page, making it easier to narrow down the available datasets.
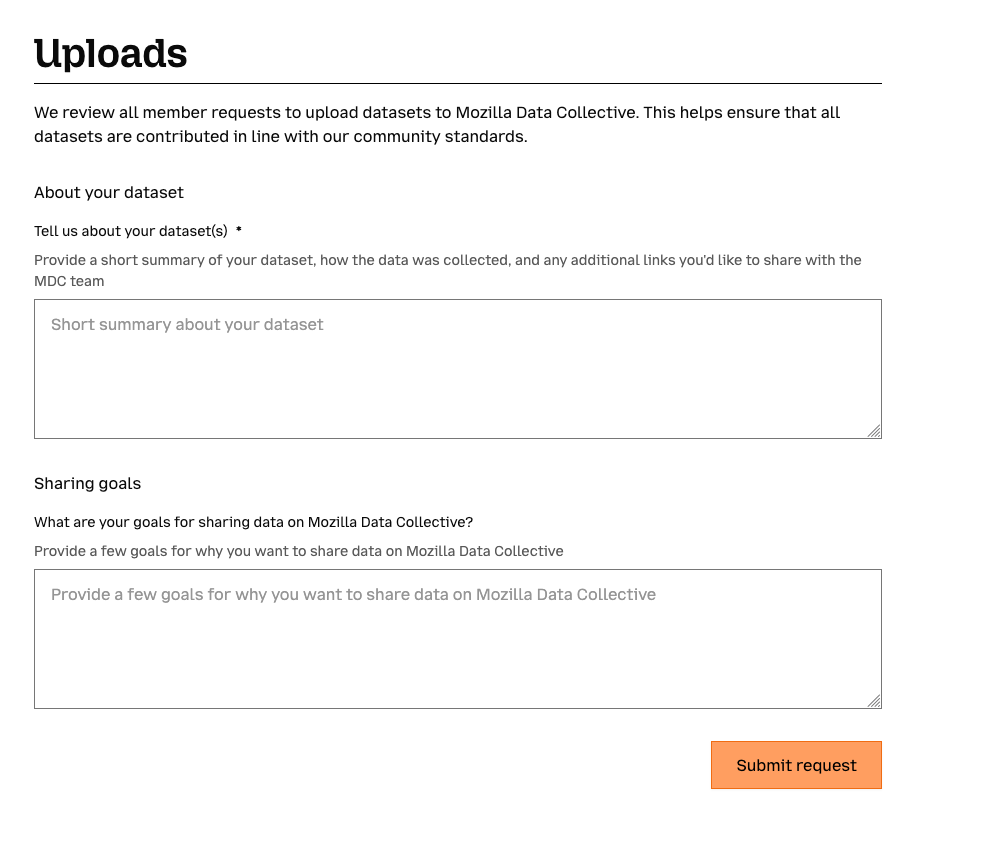
- New information requested when becoming an uploader. When you request to upload datasets to MDC, you will now be asked to fill out a short form with additional information about your datasets. Previously, the process for being approved had a member of our team emailing to collect this information. By making it part of the request flow, our team can more quickly review requests and get uploaders approved sooner!
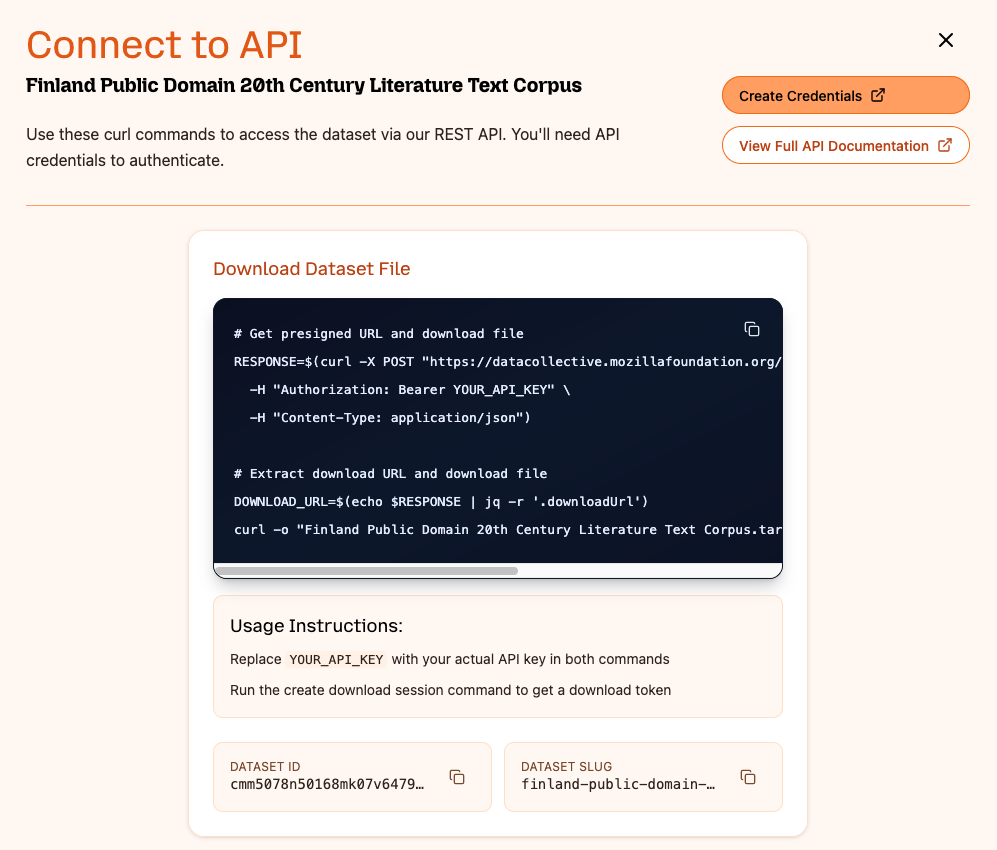
- The MDC API can now return a dataset via its slug, rather than ID. The dataset slug can be found in the 'Connect to API page' once terms and conditions have been agreed to for a given dataset.
Fixes
- The Common Voice English Spontaneous Speech 1.0 dataset has been made public to account for the fact that v2.0 was not released
New Datasets
Institute of African Digital Humanities
Lingala-TTS-Dataset | Mozilla Data Collective
The dataset contains audio and text resources in Lingala, a Bantu language spoken in the Republic of the Congo (also known as ‘Congo Brazzaville’) and the Democratic Republic of the Congo (DRC). These resources are suitable for TTS and ASR tasks and consist of the following: - 8,572 audio clips totalling 4 hours, 25 minutes and 54 seconds;
- an audio mapping file containing 8,572 lines.

Kaltepetlahtol
Daily Expressions in Highland Puebla Nahuatl | Mozilla Data Collective
A corpus of more than 1,000 common expressions in Highland Puebla Nahuatl, annotated for child-directedness and code-switching. 80% of the phrases are accompanied by Spanish translations. All names mentioned in the sentences have been anonymized.

Zacatlán Tepetzintla Nahuatl ASR Dataset | Mozilla Data Collective
An ASR dataset of Zacatlán-Ahuacatlán-Tepetzintla (Western Sierra Puebla) Nahuatl, ISO 639-3 nhi. This is a derivative work of the Zacatlán Tepetzintla Nahuatl Audio and Transcriptions datasets. It consists of the subset of larger audio dataset with transcriptions (approximately 14 hours) converted to the Mozilla Common Voice Scripted Speech format. The original stereo audio has been split and aligned with the parsed transcriptions.

MDC Community Concierge
Finance Sentences - North American Spanish | Mozilla Data Collective
This is a public domain corpus of North American Spanish sentences in the finance domain. The corpus was collected in the second half of 2023 in aid of the Mozilla Common Voice project. The dataset contains 79,655 clean sentences (1,325,013 tokens) from nine distinct federal domains. It also contains a total of 209,061 sentences (4,125,637 tokens) of sentences without
cleaning.

Cuentos en Kʼicheʼ leídos en voz alta | Mozilla Data Collective
Una colección de cuentos (audio y texto) en la lengua Kʼicheʼ. 1 hora 51 minutos de audio con 726 oraciones (8,283 palabras) de texto, del Currículo Nacional Base de Guatemala.

Cuentos en Mam leídos en voz alta | Mozilla Data Collective
Una colección de cuentos (audio y texto) en la lengua Mam. 40 cuentos, un total de 1 hora 23 minutos de audio con 958 oraciones (7,441 palabras) de texto, del Currículo Nacional Base de Guatemala.

MDC Curators
CorCenCC: Corpws Cenedlaethol Cymraeg Cyfoes | Mozilla Data Collective
The CorCenCC corpus contains over 11 million words (circa 14.4m tokens) from written, spoken and electronic (online, digital texts) Welsh language sources, taken from a range of genres, language varieties (regional and social) and contexts. The contributors to CorCenCC are representative of the over half a million Welsh speakers in the country. The creation of CorCenCC was a community-driven project, which offered users of Welsh an opportunity to be proactive in contributing to a Welsh language resource that reflects how Welsh is currently used.

MIT
ATLAS Cross-Lingual Transfer Matrix | Mozilla Data Collective
This matrix is helpful for determining what languages to train a language model with. Given a Target Language, we hope to optimize the performance for (shown as rows), we estimate how beneficial it is to train with each Source Language (shown in the columns). The scores are empirically derived, from 750+ training experiments in the ATLAS multilingual scaling laws paper: https://arxiv.org/pdf/2510.22037. Higher scores indicate greater synergy, whereas lower scores indicate more interference.

OpenCSG
Finweb-Edu-Chinese-v2.2 | Mozilla Data Collective
Fineweb-Edu-Chinese v2.2 is the updated Fineweb-derived dataset of refined Chinese educational web content. It enhances content quality and expands education-stage coverage, fitting education-focused LLM training & educational AI tools. Get the dataset at www.opencsg.com.

Taruen
Finland Public Domain 20th Century Literature Text Corpus | Mozilla Data Collective
This corpus contains a curated collection of public domain literature from Finland, featuring works by authors who died between 1901 and 1955. The dataset captures the literary landscape of early 20th-century Finland and includes independent texts in both of the country’s official languages: Finnish (fi) and Swedish (sv). The texts were programmatically extracted from Project Lönnrot, a volunteer-driven digital library. To ensure linguistic relevance for modern NLP tasks, the extraction pipeline strictly filtered for works published in 1901 or later. Language codes for each text were dynamically detected using CLD algorithms. The corpus comprises approximately 69.1 million words across multiple plain text files, with each file prefaced by structured YAML front matter containing relevant metadata (title, author, year, source URL, language), followed by the original project’s boilerplate preamble enclosed in delimiter tags, and finally the literary text proper. All included works are fully in the public domain under Finnish and EU copyright law.

Polish Public Domain 20th Century Literature Text Corpus | Mozilla Data Collective
This corpus contains a curated collection of 54 iconic Polish literary works, including major novels, sprawling multi-volume historical epics, and documentary prose from the late 19th and early 20th centuries. The dataset features the complete canonical works of literary titans such as Władysław Reymont, Stefan Żeromski, Henryk Sienkiewicz, Bolesław Prus, Józef Ignacy Kraszewski, Eliza Orzeszkowa, Tadeusz Dołęga-Mostowicz, and Zofia Nałkowska. All texts utilize modern Polish orthography (post-1936 standard) to ensure consistency and utility for training contemporary language models. The corpus comprises approximately 4.2 million words across multiple plain text files, with each file prefaced by structured YAML front matter containing relevant metadata (author, year, source URL). All included works are fully in the public domain under Polish law.

Dolgan Folklore Text Corpus | Mozilla Data Collective
This corpus contains a curated collection of 19 Dolgan fairy tales (15,618 words) digitized from a 2000 academic volume published in Novosibirsk. The Dolgans are the northernmost Turkic-speaking people, and their language is highly endangered. This dataset provides clean, structured data designed to catalyze machine learning and NLP research for low-resource languages, empowering the community to revitalize the Dolgan language. The corpus is structured in plain text files with YAML front matter metadata. It was created with the generous contribution of digitized texts from Karina Sheifer at Dartmouth College, with additional digitization and proofreading by Taruen.

Kyrgyz Folklore Text Corpus | Mozilla Data Collective
This corpus contains a curated collection of Kyrgyz folklore texts, including fairy tales, magical tales, tales of everyday life, proverbs, sayings, and aphorisms. The content was digitized from 5 academic volumes published in Bishkek between 2016 and 2017, sourced from the electronic collections of the Central Scientific Library of the National Academy of Sciences of the Kyrgyz Republic. The corpus is structured in plain text files with YAML front matter metadata—notably utilizing the Common Turkic Alphabet for titles—and includes 427,527 words total (338,937 in tales, 71,619 in proverbs, and 16,971 in aphorisms). Text extraction was performed via OCR and LLM processing, followed by strict human proofreading to guarantee accuracy and exclude any hallucinations.

Tbilisi State University
GeoLogicQA: An LLM Benchmark for Logical Reasoning in Georgian | Mozilla Data Collective
GeoLogicQA is a manually-curated logical and inferential reasoning dataset for the Georgian language (a Kartvelian language). Designed to evaluate deep language understanding, the dataset bypasses simple pattern recognition in favor of multi-step deduction, reading comprehension, and arithmetic problem-solving. It aims to address the gap in evaluation benchmarks for low-resource languages.

Community
Thorsten-Voice Dataset 2021.06 Emotional | Mozilla Data Collective
Thorsten-Voice Dataset 2021.06 (emotional) is a German emotional speech dataset recorded by Thorsten Müller and audio-optimized by Dominik Kreutz. It contains 2,400 recordings representing eight distinct emotions. The dataset is released under CC0 to enable unrestricted research and commercial use.

Thorsten-Voice Dataset 2022.10 | Mozilla Data Collective
Thorsten-Voice Dataset 2022.10 is a high-quality German neutral speech dataset recorded by Thorsten Müller and audio-optimized by Dominik Kreutz. It contains 12,450 phrases with more than 11 hours of clean speech audio. The dataset is released under CC0 to enable unrestricted research and commercial use.

Thorsten-Voice-44kHz-Full | Mozilla Data Collective
TV-44kHz-Full is a high-quality German speech dataset containing approximately 40 hours of transcribed recordings (38,000+ files) by Thorsten Müller, a single native male speaker. It combines multiple Thorsten-Voice subsets (neutral, emotional, and Hessian dialect) in original 44.1 kHz sampling rate. The dataset is released under CC0 to enable unrestricted research and commercial use.

Persian VOA Corpus 2003-2008 | Mozilla Data Collective
VOA news articles in Persian (Farsi) from 2003 to 2008. Each entry begins with the original URL, the date of publication, and the headline, in the following format: # File: www...
# Date: 2003-01-01
# Headline: ...
The text of the article…

Thorsten-Voice Dataset 2021.02 | Mozilla Data Collective
Thorsten-Voice Dataset 2021.02 is a high-quality German neutral speech dataset recorded by Thorsten Müller and audio-optimized by Dominik Kreutz. It contains 22,668 phrases with more than 23 hours of clean speech audio. The dataset has been publicly available for several years and is released under CC0 to enable unrestricted research and commercial use.

Bojonegoro Javanese TTS | Mozilla Data Collective
The Bojonegoro Javanese TTS is a speech synthesis dataset containing more than 8 hours of audio recordings, recorded by native speakers of the Javanese language, specifically the Bojonegoro dialect from East Java, Indonesia. This dataset represents the Bojonegoro dialect of Javanese as well as variations of the Aneman dialect. The recordings cover a variety of everyday topics that describe phenomena in daily life in the Bojonegoro area, East Java, Indonesia. The language features in the Bojonegoro Javanese dialect include the use of code-mixing and code-switching between Javanese, Indonesian, and English, reflecting the multilingual nature of the community. This mixing occurs because certain words do not have equivalents in Javanese and are more commonly used in everyday conversation. Therefore, this dataset is suitable for non-commercial linguistic research and can be used to explore phonological and lexical variations in Javanese, particularly the Bojonegoro dialect in East Java, Indonesia.



