Your datasets, under your control: Mozilla Data Collective at PyConAU in Melbourne, Australia
Kathy Reid's presentation to PyConAU in Melbourne, Australia covers tokenomics, harvesting tokens, and how Mozilla Data Collective offers a better way forward.


This weekend, Kathy Reid will present at PyConAU in Melbourne, Australia about the upcoming Mozilla Data Collective (MDC) platform - a sister platform to Common Voice.
In this blog post, we preview Kathy’s talking points, and show how you can get involved in MDC.
Tokenomics: why human-generated data is so valuable
Kathy will first give an overview of tokens - building blocks of data - and how large language models work by creating relationships between tokens. AI models need ever-increasing volumes of tokens – billions and trillions. In fact, estimates for the the volume of training data required by GPT-5 suggest that it was trained on 114 billion tokens of data - orders of magnitude more data then earlier models like GPT-2 and GPT-3.
This increase in demand for training data is shown in the image below
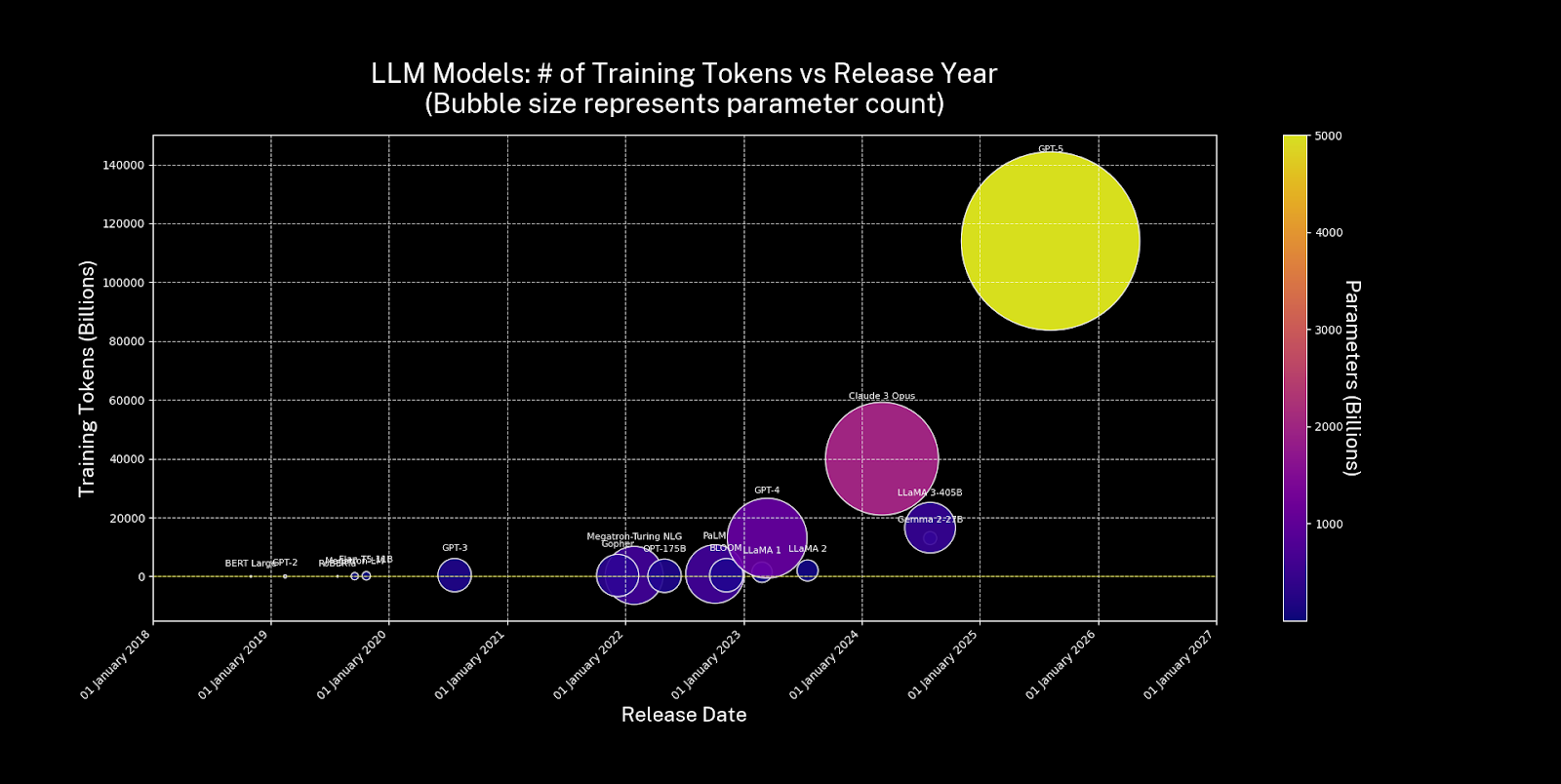
Source: https://github.com/KathyReid/token-wars-dataviz
And we’re reaching the limits of just how much data is available on the open web. And while synthetic data - data produced by generative models - can help fill the gaps in some cases, training those same models with synthetic data leads to a condition called model collapse.
So, just like fossil fuel, tokens are becoming scarce, rare, and contested
Token harvesting
Extractive practices
And harvesting tokens to train AI is now big business. But tokens are scraped in ways that are exploitative.
Many system administrators now spend a lot of time and energy preventing bots and scrapers from overloading their infrastructure.
And harvesting tokens is not just exploitative of hosting infrastructure - token harvesting also extracts value from data creators - whether that’s writers, or artists, or corporations who put content on the web. And it’s also exploitative of the workers who are paid pennies to label, or moderate the content that is scraped. So, it’s exploitative all around - technically, from an infrastructure perspective, creatively and from a labour perspective.

Nicola Heath, “Australian authors challenge Productivity Commission’s proposed copyright law exemption for AI”, ABC News, 13th August 2025
Concentration of power
Token harvesting also works to concentrate power - meaning that it’s a small group of players shaping AI innovation. If you have a lot of data - like Reddit or Stack Overflow - then you can block certain scrapers, and only allow some companies to scrape your data - in exchange for wads of cash - which is exactly what Reddit and Stack Overflow have done, inking exclusive agreements with OpenAI.
Not everyone is represented in harvested data
And importantly, all those billions of tokens that have been scraped from the web don’t represent everyone. The language, the words, the sentences that are harvested represent a particular culture - often a dominant culture - but not everyone. Compare the writing on Reddit with the Washington Post or with a Tumblr blog - they’re vastly different styles, word choices and forms of expression.
Moreover, the internet is predominantly English - so token harvesting for AI training also reduces the opportunities for AI to develop in the other 7000 languages still spoken today
The internet is also full of biases - sexism, racism - and if we scrape the internet blindly and feed it to AI models, they’re going to inherit those biases.
Bulldozing rights
And current approaches to token harvesting bulldoze rights. They don’t respect values like data sovereignty and CARE principles for the treatment of Indigenous data.
Language encodes culture. Language encodes history. Language encodes stories, and songs and dreams. And if we scrape language data without permission, we’re scraping culture and scraping history and scraping stories and scraping songs and dreams.
The Mozilla Data Collective: A better way
In an industry that relies on extractive practices, Mozilla Data Collective is rebuilding the AI data ecosystem - with communities at the centre.
So, what are the two sides of the platform?
Data contributors
Data contributors are those people who make datasets available through the Mozilla Data Collective platform.
Researchers and non-profits often have valuable data, and want to help that data be discovered to increase its impact - especially because it’s often expensive to produce
Creatives, media organisations and SMEs want generate revenue and benefits for the people who’ve created the data - the words, the images, the creative works.
And governments, funders and public knowledge organisations also have datasets they want to make public - unlocking their benefits for AI innovation.
But at the moment, there are limited options for these data contributors to share their data on their terms.
Data consumers
And on the other side of the platform we have Data Consumers - people who need data.
Model trainers and data engineers need high quality datasets - human, authentic, curated with care, ready for training.
Technical organisations - those deploying models into production - want to be able to connect with the communities behind datasets - so they can ask questions like “where did this data come from” or “what decisions are behind this data” and “how does this data reflect community values?”.
And compliance professionals want to be able to de-risk their use of data by understanding its context - where and who and what it came from.
Again, there are limited options for data consumers to obtain high quality, human data in a compliant and ethical way.
Mozilla Data Collective - a better way
The Mozilla Data Collective brings together these two groups - data contributors and data consumers - unlocking data abundance by giving people and communities control over their data.
Data contributors can promote their datasets, see how they’re being shared, and unlock new value by combining them with other datasets. Data consumers can find the data they’re looking for, connect with communities who created that data, and know that they have supply chain transparency.
Join us!
And we’d love for you to join us!
And you can connect with us on social media.



Slides
You can see the slides from the talk above (PDF, 4.2MB)
Further reading
- Associated Press. AI startup Anthropic agrees to pay $1.5bn to settle book piracy lawsuit. The Guardian. September 5, 2025.
- Cummins M. How much LLM training data is there, in the limit? Educating Silicon. May 9, 2024.
- Global Indigenous Data Alliance. CARE Principles for Indigenous Data Governance.
- Hao K. Artificial intelligence is creating a new colonial world order. MIT Technology Review. April 19, 2022.
- Heath N. Authors warn AI copyright exception a “free pass” for Big Tech to steal work. August 13, 2025.
- Jones PL, Mahelona K, Duncan S, Leoni G. Kaitiaki: closing the door on open Indigenous data. International Journal on Digital Libraries. 2025;26(1):1. doi:10.1007/s00799-025-00410-2
- OpenAI. OpenAI and Reddit Partnership. May 16, 2024.



